
This is a little project to create a recommender system to find mentors inside an organization, using Natural Language Processing. It started as an excuse to build a data visualization I had in mind: an interactive word cloud that did something. When I started, I didn’t know anything about Topic Modeling, Topic Extraction, or Natural Language Processing; and fell head first into a rabbit hole.
TL;DR:
Topic extraction is deep and potentially rewarding. Sanitize properly. SpaCy and Gensim are your friends. Search YouTube for knowledge. This is related to “Topic Extraction from Scientific Literature for Competency Management” and “The Author-Topic Model for Authors and Documents“. Get the code of this project at https://github.com/danielpradilla/enron-playground
General Description
Imagine we would like to know who is the best person to ask about a subject inside a company –a potential mentor. One way would be to infer each person’s speciality from their main body of work: emails.
If I lived in another world in which privacy is not an obvious concern –or if I worked in Google– reading other people’s email would be totally kosher. In the normal, privacy-complaint world, this remains a purely academic exercise.
However we do have access to a publicly-released corpus of emails to work with: the Enron email dataset.
My first idea was to use a named entity recognizer (NER), because if one were designing a recommender system for an energy company, one of the use cases would be to suggest whom to ask about a very specific technical issue. At the time, I found SpaCy to have a nice NER for python.
To identify the mentors, I assumed that whomever wrote an email about a subject, knew something about it. I’m not that naive, I know that’s not always the case, but hey, that’s what I had! I could create a distribution subject-person and argue that the ones at the top of each subject knew something about it. Looking at the corpus, it seemed I had to extract the “from” field and the body of the email to build this distribution. I could use the email module and Beautiful Soup for HTML emails. With a little bit of text mining, I could transform this bunch of files –over 600,000!– into a structured dataset.
Before I dived in, I had to clean the text. I thought that a couple of regular expressions would suffice but these emails had some surprises in store:
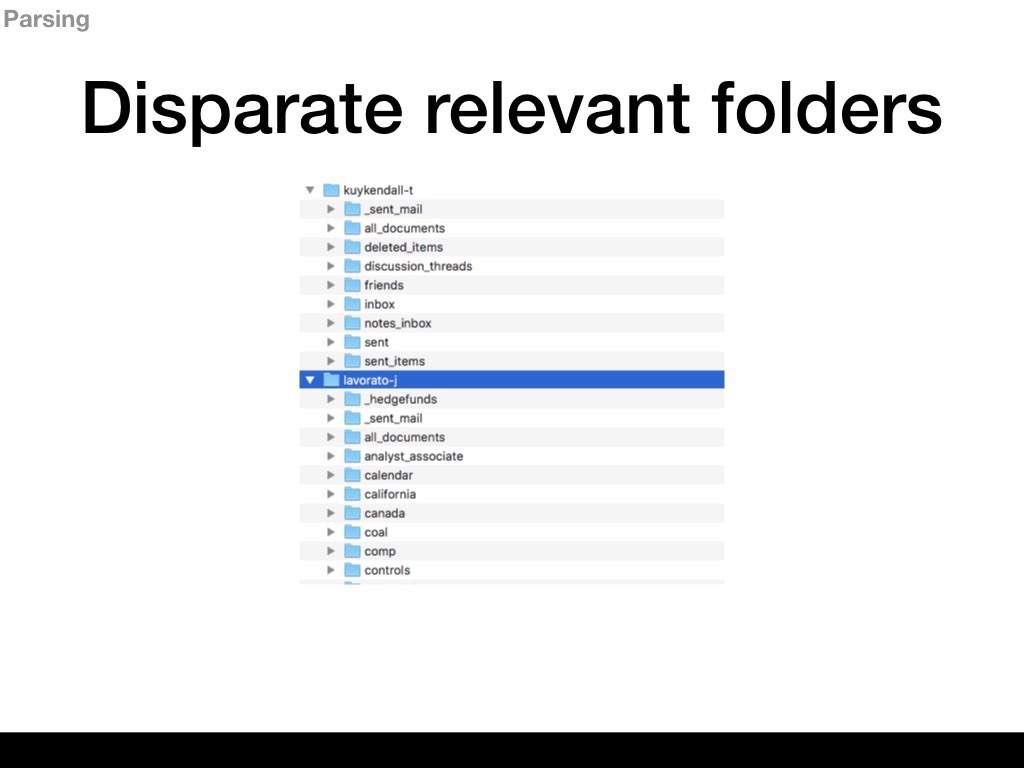
- The emails themselves were stored in folders that mirrored the folder structure of the owner’s email client. I wasn’t counting on people using different email clients that exported different folder structures.
- There was a considerable amount of repeated emails, with multiple copies stored in different folders. I needed to ignore those if I wanted to build an accurate distribution of person-subject.
- A lot of these emails were responses or email threads. I needed to find a way to extract only the original text that belonged to the author of the email. Otherwise, I could mis-attribute the text.
- I found a ton of extraneous characters that rendered the text unreadable.



This is a group of regex expressions that produced sufficiently-clean bodies.
stop_regexes = [
re.compile('----\s*Forwarded by'),
re.compile('----\s*Original Message'),
re.compile('_{20}'),
re.compile('\*{20}'),
re.compile('={20}'),
re.compile('-{20}'),
re.compile('\son \d{2}\/\d{2}\/\d{2,4} \d{2}:\d{2}:\d{2} (AM|PM)$', re.I),
re.compile('\d{2}\/\d{2}\/\d{2,4} \d{2}:\d{2} (AM|PM)', re.I),
re.compile('^\s?>?(From|To):\s?', re.I),
re.compile('LOG MESSAGES:',re.I),
re.compile('=3D=3D',re.I),
re.compile('Memo from.*on \d{2}\s(?:Jan(?:uary)?|Feb(?:ruary)?|Mar(?:ch)?|Apr(?:il)?|May|Jun(?:e)?|Jul(?:y)?|Aug(?:ust)?|Sep(?:tember)?|Oct(?:ober)?|(Nov|Dec)(?:ember)?),', re.I),
re.compile('Outlook Migration Team', re.I),
re.compile('PERSON~', re.I),
re.compile('>>>', re.I)
]
Being a static data set, I didn’t have to do this every time, so I stored the extracted and sanitized data. Since I was going to be creating a web application that most probably would feed from a REST endpoint, it would be beneficial to store the data in a format that is the closest to what the API provides. I went with MongoDB as a database, that way I could “think in JSON” all the way from the database to the user interface.

(this is close to the approach I took in that other post about building a web front-end with falcon and gunicorn)
If the emails were to be ingested dynamically, I would’ve chosen the Elastic Stack for the task, but since it was a one-off thing, I created a python script to sanitize and then store the data in Mongo. That first script took altogether around 30 minutes to identify and store 251K unique records. In order to avoid duplicates, I created an index out of the “from”, “subject” and “date” fields. Arguably, few people are capable of sending one email with different subjects at the same exact millisecond!
Text Mining – Entity Extraction
Like I mentioned above, my plan was to use a Named Entity Recognizer. I was looking for subject matter experts and subject matter experts deal with named entities, right? I could get the frequency of utilization of each entity per author and infer from that how much the sender knows about a subject. Or, at least, its familiarity with the subject.

I invested a few hours on that. I used spaCy to lemmatize the words –an important step, as I wanted to build my model using root words that appear in the dictionary, words that made sense. I wanted “writer”, “write” and “writing” to be turned into “write”, not “writ”. Lemmatization is generally slower than stemming, but from the user-interface perspective produces more readable results.
As I was going deeper into the subject, I stumbled upon the wonderful world of topic extraction. This was my first time doing NLP. So I called Héctor Palacios, which is my AI/NLP/ML go-to-guy, and he confirmed that what I was attempting to do was topic extraction and that I should look into Latent Dirichlet Allocation (LDA).
LDA produces a list of topics in the form of a distribution of words per topic. The output looks like a bunch of words grouped together in lists. However, I was hellbent on finding those entities with the NER. LDA is an unsupervised algorithm and that seemed a lesser solution for me. A bag of words around certain topics? How can that be better than “this person writes a lot about the XYZ generator”? Also, how could topics made out of bag of words possibly make sense?
However, the NER approach had a problem: I was going to need to manually parse a distribution of all the detected entities and manually build some kind of related entities dictionary. Because the person who knows a lot about the XYZ generator might also know about the ABC generator, but hasn’t said much about it. I would have to manually enrich the detected entities. So, 15 hours into this project, I decided to give LDA a try.
Natural Language Processing – Topic Extraction
Using gensim –which seems to be the most popular python library for topic modeling,– I ran a simple topic extraction just to see what I got in the output. Each line is one topic:

See that natural almost-self-explanatory grouping?
- Topic #2 is about a gas installation in Shackleton, Saskatchewan (with a bit of Sara Shackleton, VP of Enron North America, thrown in the mix).
- Topic #7 is arguably about the newsworthy California energy crisis.
After seeing the results I realized that I needed to start trusting the literature produced by people much more intelligent than me!
Given the results above I revised the approach:
- Find the topics in the corpus.
- Get the words for each topic
- Get all the words used by all the authors
- Calculate frequency of word usage per author
- Find the topics that match each author’s word frequencies
In the example above, if a person used the words “LNG”, “gas” and “Shackleton” a lot, arguably this person is a candidate to know a lot about topic #2.
As I was gearing towards creating this distribution of word frequencies, I found that the gensim library actually provides author-topic modeling, which outputs the topic distribution of an author. Exactly what I was looking for. The author-topic model returns a probability distribution of how likely a topic is to be expressed by an author. I found two relevant papers about what I was attempting to do: “Topic Extraction from Scientific Literature for Competency Management” and “The Author-Topic Model for Authors and Documents”
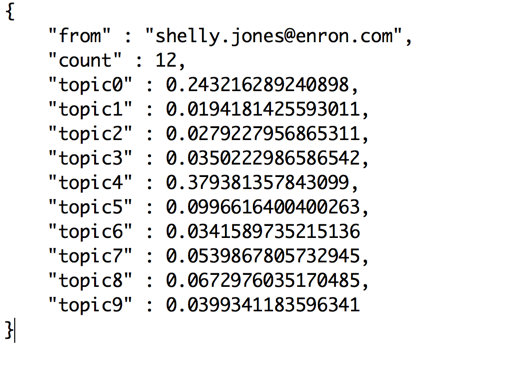
How do I know if the list of topics is a “good” list of topics?
Gensim provides an automated way to measure topic coherence. A good model will generate coherent topics –topics with high topic coherence scores.– Good topics are semantically-coherent, all their words seem to go together and it’s relatively easy for a person to describe the topic with a short label. If you want to know how this measure was designed, read “Optimizing Semantic Coherence in Topic Models”
Topic coherence is affected by the number of topics you choose to extract and the number of iterations you use to build the model. A higher number of iterations will produce a better model, but it will take longer. In some cases, you will get better results by reducing or expanding your desired number of topics. I started from 5 topics and 3 iterations and waited almost forever for a not-very-good list of topics. I ended up with an acceptable list at 10 topics and 2 iterations.
Check out “Exploring the Space of Topic Coherence Measures” if you want to know about other coherence measurements.
I applied additional filtering before building the model, excluding empty emails, 2-word emails, all stop words and high-occurrence words –words which appeared in more than 50% of the emails.
The latest run took 191 minutes on a single thread, this is the list of topics and how I labelled them.
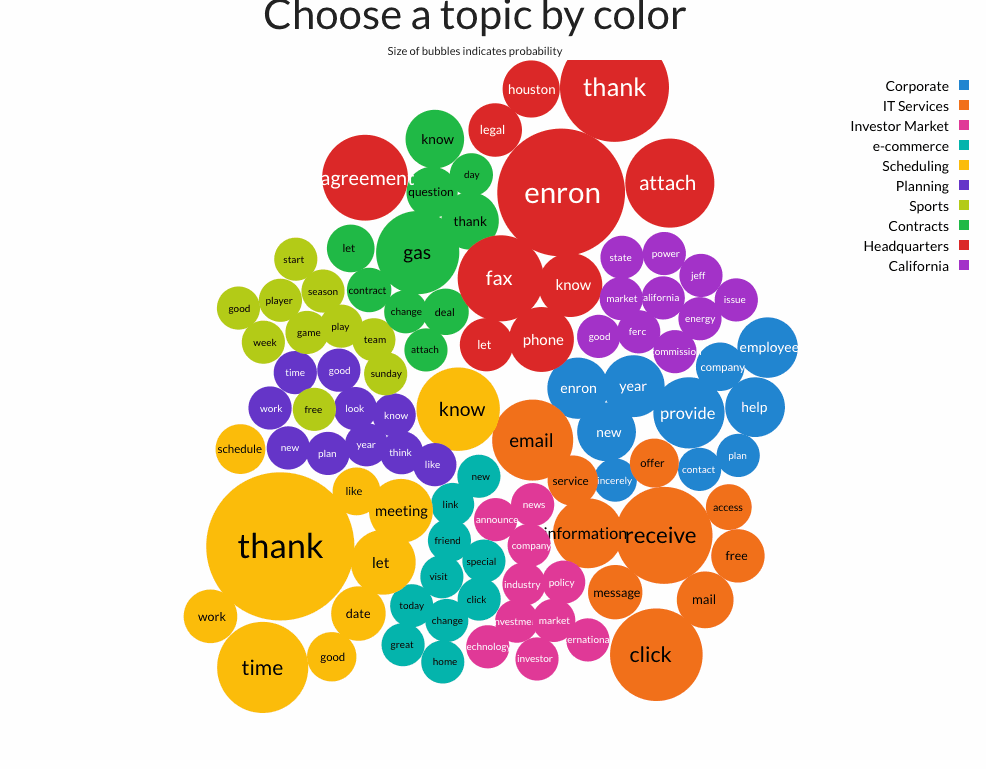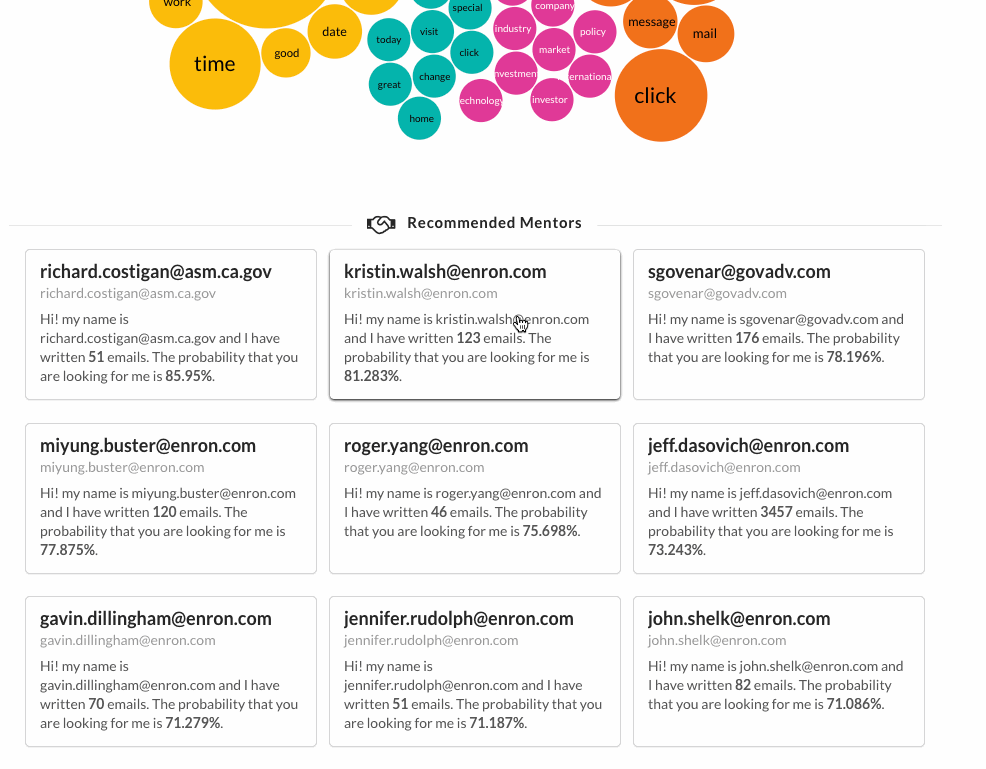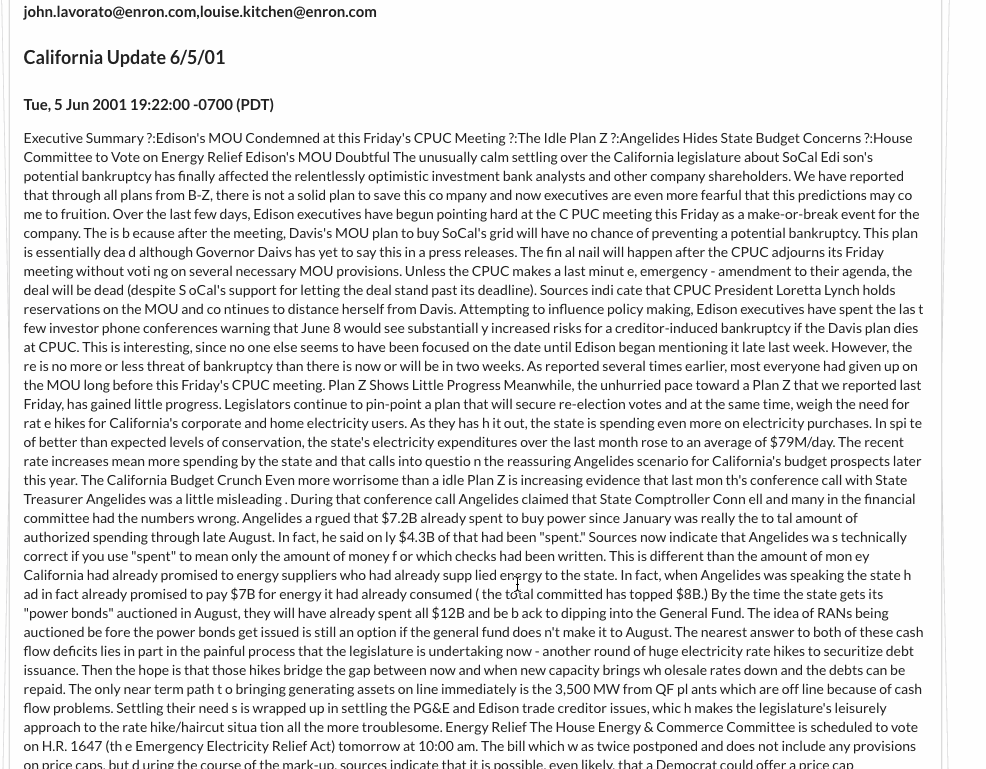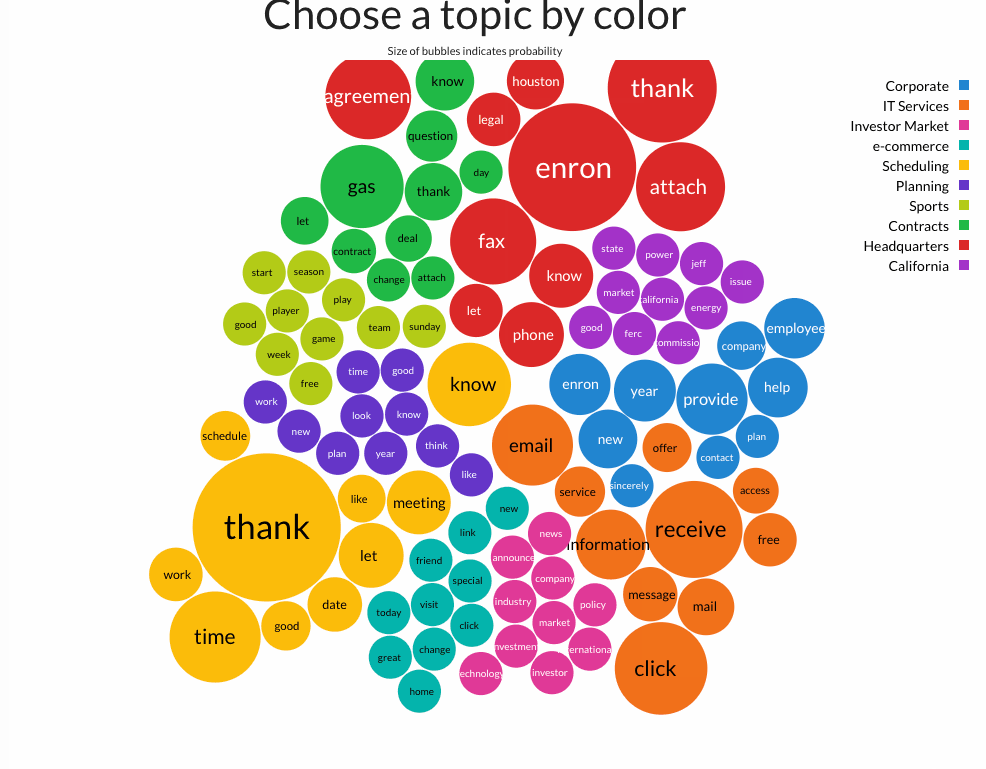
- Topic 1 Corporate: provide year enron employee help new company contact sincerely plan
- Topic 2 IT Services: receive click email information mail message free service offer access
- Topic 3 Investor: industry investment investor technology news international market policy company announce
- Topic 4 e-commerce: visit click great special today home friend link new change
- Topic 5 Scheduling: thank time know let meeting date work schedule good like
- Topic 6 Planning: look know like think good year new time work plan
- Topic 7 Sports: game play good week season team sunday player start free
- Topic 8 Contracts: gas know thank question let deal contract day change attach
- Topic 9 Headquarters: enron thank attach fax agreement phone know houston legal let
- Topic 10 California: california market good issue jeff ferc state energy commission power
I stored all the topics and all the author-topic distributions in MongoDB.
User Interface – API and web application
As a reminder, the whole idea is to build a recommender system, so the application needed at least three main functionalities:
- Show the list of topics. Allow the user to select a topic.
- Show the list of experts for the selected topic
- Show a sample of the emails produced by the selected expert, as a way to confirm that our selection appeals to us.
I used gunicorn to create a simple API that provides JSON objects for the topics, the author-topics and the body of the emails.
I created a chart D3.js that showed a bubble chart word cloud, color-coded by topic, in which the radius of the bubble is proportional to the probability of the word appearing in that topic.

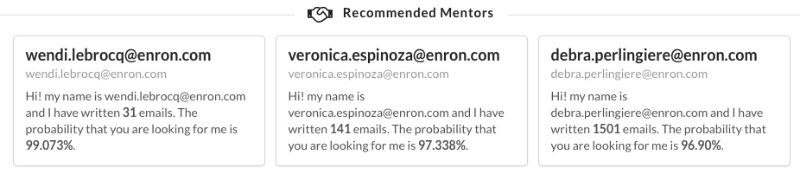
When you click on any word of a topic, 9 information cards appear, each one with a recommended mentor.
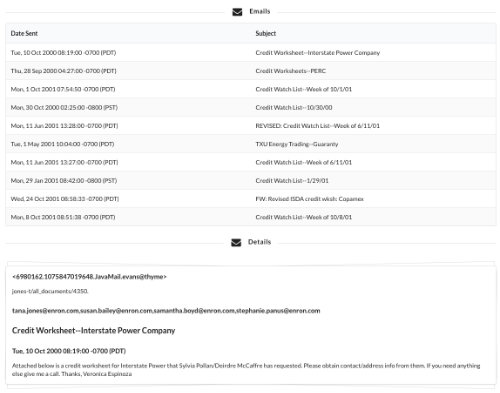
When you click on a mentor, a list of their emails appear and if you click on a particular email, you can inspect the body below.
For the user interface, I built a web page using the Semantic UI framework semantic get it?, and this is an animation of how it works:
This visualization was inspired by The New York Time’s At the Democratic Convention, the Words Being Used.
What could be better
I was partially satisfied with this list of topics, I did not like some of the terms proposed by the model –a lot of “thanks” in there– and I have the suspicion that the data was skewed towards a few very-prolific emailers. A way to improve these results would be to normalize the sample of the users, so that they are all equally represented. Another thing that could be attempted is to build a Frankenstein between this and a NER, and throw everything in Elastic Search, to have a search engine of Topics and Entities.
I would argue that a recommender system that involves people should weight social reputation when possible. Maybe we could improve this model if we knew the job description of each author. Perhaps weighting people according to their expected speciality or their position in the hierarchy could help us fine tune the results.
More
If you are interested in this topic, I can recommend:
- Applied Text Mining course (Coursera)
- Topic Modeling with Python (YouTube)
- Recommender Systems (YouTube)
- Introduction to Recommender Systems course (Coursera)
You may find all the code for this project at https://github.com/danielpradilla/enron-playground